
 Wie viele andere auch habe ich jahrelang meine Webseite offline bearbeitet und dann per FTP-Client auf den Webspace hochgeladen. Auch mit WordPress hat sich an diesem grundlegenden Ablauf nicht viel verändert. Vor ein paar Monaten war ich es jedoch leid und habe einen neuen Workflow eingeführt: Meine Webseiten sind sowieso in einem Git-Repository verwaltet, damit ich einen Überblick behalte, was sich geändert hat. Da ist es nur ein kleiner Schritt, das Repository auf dem Webspace zu klonen und alle Änderungen per Git-Checkout hochzuladen. Man kann dann also lokal ändern und alle Änderungen (und auch nur diese) mit einem Knopfdruck hochladen.
Wie viele andere auch habe ich jahrelang meine Webseite offline bearbeitet und dann per FTP-Client auf den Webspace hochgeladen. Auch mit WordPress hat sich an diesem grundlegenden Ablauf nicht viel verändert. Vor ein paar Monaten war ich es jedoch leid und habe einen neuen Workflow eingeführt: Meine Webseiten sind sowieso in einem Git-Repository verwaltet, damit ich einen Überblick behalte, was sich geändert hat. Da ist es nur ein kleiner Schritt, das Repository auf dem Webspace zu klonen und alle Änderungen per Git-Checkout hochzuladen. Man kann dann also lokal ändern und alle Änderungen (und auch nur diese) mit einem Knopfdruck hochladen.
Voraussetzungen: Ihr braucht SSH-Zugang zum Server, außerdem muss dort Git installiert sein. Bei meinem Provider Domainfactory ist das schon mit mittleren Packages gegeben. Die Ablage des Repositories auf dem Server braucht natürlich auch mehr Platz als nur die Dateien an sich dort zu lagern. Ihr müsst also euren Webspace im Auge behalten!
Wieso Git? Weil es relativ simpel verfügbar ist. Ich bin an sich kein Freund des komplexen Workflows und komme mit Subversion viel besser zurecht. Aber es gibt nun mal keine brauchbaren, frei verfügbaren SVN-Services, und auf Shared Hosting kriege ich sowas auch nicht ohne weiteres aufgesetzt. Für Git gibt es genügend Angebote, ich habe meine Repositories bei Bitbucket abgelegt, wo eine kleine Anzahl private Repositories kostenlos sind. Und vor allem: Seit kurzem gibt es mit Source Tree einen brauchbaren Windows-Client für Git!
Der grundlegende Workflow sieht so aus: Man legt ein lokales Git-Repository an und fügt die Dateien hinzu. Änderungen werden erst mal nur in dieses lokale Repository committet, das in einem “.git“-Verzeichnis auf der Festplatte liegt. Nun kann man dieses Repository jedoch anderswo klonen und dem eigenen Repository als „remote“ hinzufügen. Bitbucket hat dazu gute Anleitungen, andere Anbieter sicher auch. Source Tree zeigt nach dem Committen fortan den „Push“-Button an, wenn man Änderungen noch nicht weiterverteilt hat. Man schiebt diese Änderungen also damit auf den Server.
Für Anbieter wie Bitbucket ist es damit getan. Man pusht die Änderungen und hat sie dann als Backup bei dem Anbieter liegen. Um damit eine Webseite darzustellen, ist jedoch etwas mehr Arbeit nötig. Das Setup sieht so aus: In einem Ordner außerhalb des vom Internet aus zugänglichen Webspaces legt man ein Repository an, welches keinen Working Tree enthält, sondern nur die Infos über die Datei-Änderungen. Dieses Repository wird dann genau wie das Bitbucket-Repository als Remote hinzugefügt, Änderungen pusht man nacheinander zu beiden Stellen. Auf dem Webspace läuft dann ein Script, das nach dem vollständigen Empfangen der Daten diese in einen Working Tree auscheckt, der von außen die Webseite darstellt.
Da dieser Beitrag vor allem mir selber als Gedächtnisstütze dient und ich das grundlegende Setup schon vor vielen Monaten gemacht habe, kann ich zum lokalen Einrichten von Git hier nicht ins Detail gehen. Rund um Bitbucket und Source Tree gibt es da aber gute Tutorials. Update 06/2020: Anlässlich des Umzugs zu meinem neuen Hoster habe ich noch mal alle Arbeitsschritte detaillierter aufgeschrieben.
Nun aber zur Verknüpfung mit dem Webspace. Vorarbeit: Es wird in Zukunft lokal und auf dem Server der gleiche Code-Stand verwendet. Alles, was sich lokal unterscheiden muss, muss also in Dateien ausgelagert werden, die dann in die .gitignore-Datei eingetragen, somit also nicht versioniert werden. Das kann z.B. eine settings.php-Datei sein, die einige Pfade oder Datenbank-Zugangsdaten enthält und manuell auf den Server geladen wird.
Schritt 1: Verbindet euch mittels SSH mit dem Server und legt dort ein Git-Repository an. Achtet darauf, einen brauchbaren Ordnernamen zu vergeben (am besten ohne Leerzeichen) und dass dieser Ordner nicht über den Webserver von außen erreichbar ist! Bei mir liegen z.B. alle extern erreichbaren Webseiten unter „/webseiten/…“, aber ich kann auf der gleichen Ebene andere Ordner anlegen, an die man nur per FTP oder SSH rankommt.
mkdir webseite_repo cd webseite_repo git --bare init
Schritt 2: Wir fügen das neue, leere Repository unserem lokalen Repository als Remote hinzu. In Source Tree wählt ihr euer Projekt aus und geht auf Projektarchiv > Remote hinzufügen. Klickt „Hinzufügen“ an und gebt dem Remote einen eindeutigen Namen, z.B. den des Providers. Als URL habe ich eingetragen: „mein_ssh_login_name@meine_domain:/pfad/zu/dem/neuen/repository“. Speichert das und probiert das Pushen aus (Button „Push“ anklicken, im DropDown ggf. den Remote auswählen, Häkchen bei Checkbox „Push“ setzen). Auf dem Server solltet ihr danach in dem Git-Ordner eine Menge neuer Dateien sehen.
Hinweis: Hier hatte ich tatsächlich ein Problem, denn der Upload dauerte beim ersten Mal einfach zu lange und wurde mit einem Timeout abgebrochen. Ich musste das lokale Repository zippen, hochladen und vor dort aus pushen (per Kommandozeile). Unschön, aber es geht, und danach macht man ja eher nur noch kleinere Änderungen. Gezippt wird der ganze Ordner incl. .git-Unterverzeichnis. Auf dem Server dann:
unzip local_repo.zip cd local_repo git push ../webseite_repo master
So, nun Schritt 3: Wir wollen automatisch die Dateien nach einem Push auf dem Server so ablegen, dass sie über den Webserver als Seite erreichbar sind. Dafür legen wir einen „post update hook“ an. Bei mir ist das ein Shell-Script, das so aussieht (erst mal lokal sichern):
#!/bin/sh export GIT_WORK_TREE=/kunden/1234567/webseiten/meine_webseite git checkout -f >> /kunden/1234567/logs/git_meine_webseite_$(date +%y-%m-%d).log rm -rf /kunden/1234567/webseiten/meine_webseite/krempel
In der zweiten Zeile wird die GIT_WORK_TREE-Variable auf den Zielpfad gesetzt. Wenn die Webseite schon läuft, könnt ihr das erst mal mit einem anderen Pfad testen und erst nach einem erfolgreichen Test auf den gewünschten Pfad umschwenken. In der nächsten Zeile wird nun Git angewiesen, einen Checkout durchzuführen und Meldungen in eine Logdatei zu schreiben. In der letzten Zeile schließlich entferne ich noch Ordner, die ich zwar aus Backup-Gründen im Repository haben will, die aber nichts auf der Webseite zu suchen haben. Dort sollten natürlich keine sensitiven Daten drinliegen, falls das Entfernen mal schiefgeht.
Diese Datei wird nun per FTP hochgeladen und hier gespeichert: „/kunden/1234567/webseite_repo/hooks/post-update“. Die Datei braucht noch Ausführungsrechte, was man mit „chmod +x post-update“ hinbekommt.
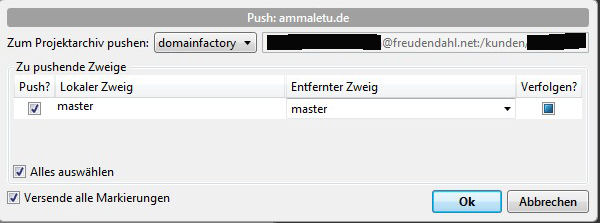
So, nun kann man das Gesamtkonstrukt testen. Lokal etwas ändern, in Source Tree committen und zum Provider pushen. Die Änderungen sollten dann in dem „meine_webseite“-Ordner auftauchen. Voilá, kein mühsames Zusammensuchen und einzelnes Hochladen der geänderten Dateien mehr. Bei größeren Updates werden diese auch zuerst am Stück hochgeladen und dann per Dateisystem verteilt, so dass die Webseite nicht unnötig lange in einem inkonsistenten Zustand ist.
Mein erster Gedanke nach dem Durchlesen dieses Textes: WTF?! 🙂
Ich persönlich bevorzuge weiterhin das gute alte FTP, da ich bisher nur meine eigenen Homepages betreuen muss, auf denen sich nur dynamisch etwas ändert, also die eigentlichen Inhalte zu 90% in einer Datenbank liegen. Auch wenn ich durchaus die Möglichkeit hätte, dank eines virtuellen Servers mein Git zu hosten. Aber der Aufwand ist mir für das bisschen Zeug zu groß. Trotzdem faszinierend, womit sich andere leute so ihre Zeit um die Ohren schlagen. 🙂 Ich kannte Versionierungssysteme bisher nur im Zusammenhang mit Softwareentwicklung.
Es war tatsächlich etwas Arbeit, aber ich bin mit dem Ergebnis sehr zufrieden. Ich nutze dieses Konstrukt für zwei völlig verschiedene Seiten: Meine uralte Highlander-Seite enthält tatsächlich die Inhalt in einzelnen PHP-Dateien, da liegt keine Datenbank dahinter. Und auf dieser Seite hier liegen die Inhalte zwar in der Datenbank, aber nicht mein angepasstes Theme und die ganzen Plugins. Beide Seiten habe ich komplett versioniert, was echt praktisch ist. Mit dem Git-Konstrukt kann ich nun einfach Änderungen machen und muss danach nicht mühsam raussuchen, welche Dateien ich auf den Server laden muss (wenn ich hier überhaupt mal was mache, kann sich das ja auch über Tage ziehen). Wenn ein WordPress-Update ansteht, kann ich das auch einfach lokal ausführen, testen und dann ggf. nur noch den Push-Knopf drücken. Ok, bei großen Updates muss man auf dem Server noch mal die Datenbank anpassen, aber ansonsten war es das. Das schlägt FTP um Längen. 🙂
Hallo!
Du sprichst mir aus der Seele. Ich arbeite sehr ähnlich und habe auch einen Artikel darüber geschrieben (http://www.bjoerne.com/php-bzw-wordpress-projekte-mit-git-verwalten-und-deployen/).
Ich hoste bei domain*go, einer Tochter von domainfactory, und alles lief immer super, aber seit einiger Zeit laufen meine deploy-Skripte nicht mehr vernünftig. Als wenn der Zugriff vom Hoster auf Bitbucket stark gedrosselt wäre. Läuft bei dir noch alles sauber?
Viele Grüße
Björn
hallo johannes,
habe lange nach einer brauchbaren info über git auf domainfactory gesucht.
hat auf anhieb funktioniert.
danke
gruss
andreas
Hi,
Danke für deinen Blog!
Eine Frage hab ich noch. Warum zwei Remote Repositories? Würde das eine beim Hoster nicht reichen? Oder wird das gilt nur dann genutzt wenn man wirklich diployen möchte? Kostet doch dann doppelt so viel Zeit oder?
Das deploy-Skript wird nicht automatisch aufgerufen oder? Falls doch, warum?
Gruß Niko
Das eine Remote Repository beim Hoster reicht natürlich. Das Repository bei Bitbucket hatte ich vorher schon und habe es beim Umbau des Workflows bestehen gelassen. Man pusht dann die Änderungen natürlich doppelt raus, was aber keinen nennenswerten Zeitverlust beudetet. Dafür hat man alles noch mal bei einem externen Anbieter liegen. Wenn mal alles schiefgeht, liegen die Daten dort noch als Sicherheitskopie. Solange man WP mit Standard-Themes und -Plugins verwendet, lohnt das sicher nicht wirklich. Aber sobald man etwas mehr Code selbst geschrieben hat, ist so ein Backup schon gut.
„Das deploy-Skript wird nicht automatisch aufgerufen oder? Falls doch, warum?“
Ich bin nicht ganz sicher, was Du damit meinst. Das Pushen der Änderungen zum Server geschieht nicht automatisch. Das finde ich auch gut so, denn es ist ja mit dem Pushen ggf. nicht getan. Bei größeren WP-Updates muss man sich danach schon noch mal einloggen und z.B. die Datenbank aktualisieren. Da will ich also auch selbst bestimmen, wann ich das mache. So kann ich auch alle Plugin-Änderungen nacheinander committen und dann am Stück auf den Server pushen. Was automatisch geht, ist das Verteilen der hochgepushten Änderungen aus dem Repository in den eigentlichen Webseiten-Ordner. Das macht der post-update-Hook automatisch.
Pingback: Git Server | Daily Work
Vielen Dank für Deine Hilfe und den persönlichen Suport per Mail. (THUMB UP) Hab den Shit jetzt geschnallt und es klappt alles wunderbar. Hatte da echt nur den Denkfehler, dass es über Bitbucked läuft…. Das mit dem Pullen is doch zu aufwändig für das Projekt aber wäre auf jeden Fall auch machbar.
Gruß aus HH
Stefan
Hallo,
ich plane, meine Website ebenfalls über git zu pflegen. Ich habe allerdings bei meinem Provider keinen SSH-Zugang und git. Aber wenn ich mir das Websiteverzeichnis beim Provider ins lokale Dateisystem mounten kann, dann müsste das doch alles mit lokalen Repositories funktionieren. Oder mache ich einen Denkfehler?
Gruß aus dem Taunus,
Andreas
Ich habe keine Zeit, das im Detail zu prüfen, könnte mir aber gut vorstellen, dass man das hinkriegt. Am besten mit einem Minimal-Beispiel ausprobieren, das dauert ja nicht lange.
Andererseits… Ein Problem dabei ist sicher, dass dann der große Vorteil des obigen Setups verloren geht, nämlich dass das Umschalten vom alten auf neuen Code-Stand auf dem Server sehr schnell geht. Ich lade die Änderungen ja alle in das unsichtbare Repository hoch (Schritt 2 in meiner Anleitung oben) und erst danach werden sie auf dem Server im Dateisystem in den eigentlichen Webseiten-Ordner kopiert (Schritt 3, über den Post-Update-Hook). Diese Dateisystem-Operation wäre dann ja in Deinem Fall keine lokale Operation mehr und würde entsprechend lange dauern. Wenn dann mittendrin die Verbindung abbricht, hast Du einen kaputten Webseiten-Stand, wie früher zu guten alten FTP-Zeiten.
Aber gut, vielleicht überblicke ich das gerade noch nicht ganz. Wenn Du Schritt 2 wie beschrieben auf dem (eingebundenen) Webspace anlegst, sind die Daten ja auf dem Server. Vielleicht geht dann das Kopieren eben doch schneller als das Hochladen. Einfach mal ausprobieren mit ein paar Dateien! Bei Erfolg ruhig auch hier posten, das interessiert sicher auch noch andere. Danke!
Zu „Aber es gibt nun mal keine brauchbaren, frei verfügbaren SVN-Services“: https://riouxsvn.com/